Su carrito
Cerrar carrito

No era tu Wi-Fi: caída de Cloudflare, colapso de su CDN y el riesgo para bancos, salud y e-commerce

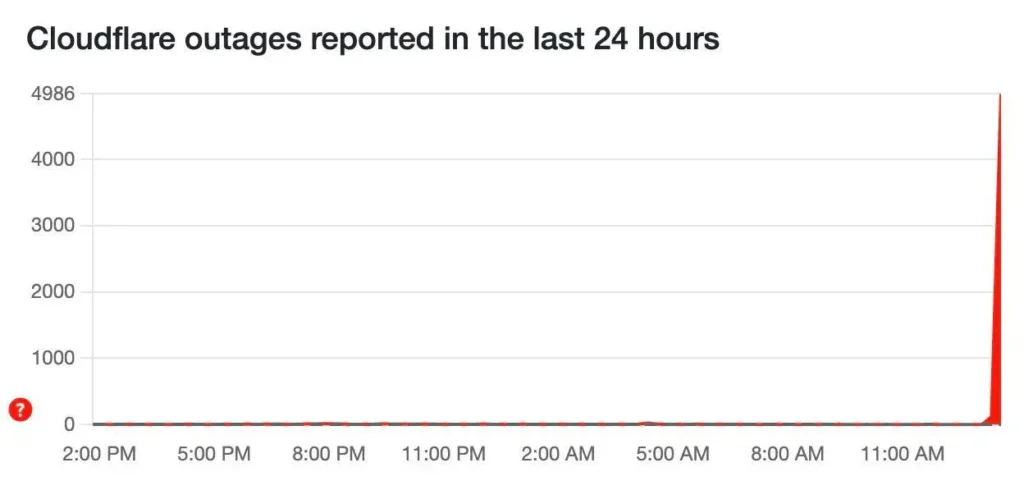

Este martes 18 de noviembre de 2025, una caída global de Cloudflare —uno de los mayores proveedores de infraestructura y seguridad de internet— dejó inaccesibles o inestables servicios como X (antes Twitter), ChatGPT, Canva, Uber, Spotify, Ikea, e incluso organismos reguladores y entidades financieras.
Durante varias horas, miles de usuarios en todo el mundo vieron errores, páginas en blanco y aplicaciones que simplemente no cargaban. El problema se originó en un fallo interno de Cloudflare relacionado con un archivo de configuración demasiado grande, usado para gestionar el tráfico malicioso, que terminó provocando un crash de sus sistemas. La empresa descartó un ciberataque y habló de un “pico inusual de tráfico” sumado a una falla de software.
Indice
ToggleCloudflare no es “una web más”, es una CDN: Content Delivery Network o red de distribución de contenido. Una CDN es una red global de servidores repartidos por el mundo que se encargan de:
Acercar el contenido al usuario: copian páginas, imágenes, videos y archivos estáticos a nodos distribuidos globalmente para que carguen más rápido.
Absorber picos de tráfico: si miles de personas entran a la vez, la CDN reparte la carga entre muchos servidores.
Filtrar tráfico malicioso: actúa como una especie de “escudo” contra ataques DDoS y bots.
Hoy, cerca de una quinta parte de los sitios web del mundo utilizan servicios de Cloudflare para rendimiento y seguridad. Cuando algo así se cae, no se cae “una página”: se siente como si una parte de internet se apagara de golpe.
Pese al alcance global del incidente, la causa original aún no ha sido clara en las primeras horas. Las primeras informaciones apuntaron a un fallo durante tareas de mantenimiento programado por Cloudflare, aunque la empresa no dio los detalles exactos.
“Cloudflare había programado un mantenimiento durante el día de hoy en diferentes áreas del mundo, pero sus servidores parecen no haber respondido bien a dichas tareas”, reportó ADSLZone. Lo que indicaría que se trata de una combinación de factores, en los que la empresa está trabajando para resolver.
La incertidumbre se ha agravado porque varias páginas especializadas en detectar caídas, como Downdetector y Down for Everyone or Just Me, también sufrieron incidentes por la dependencia de la infraestructura de Cloudflare. Así, comprobar el estado real de muchos servicios es aún más difícil y, ante la interrupción de los servicios, se hace más complicado confiar en los datos reportados por estas plataformas.
Este incidente vuelve a poner sobre la mesa un tema de arquitectura que muchas empresas han ido postergando:
Dependencia extrema de un solo proveedor para CDN, DNS, seguridad y performance.
Falta de estrategias multi-CDN o planes de contingencia para desviar tráfico rápidamente si el proveedor principal falla.
Escasa práctica de pruebas de resiliencia (simular caídas de proveedores clave, caos engineering, etc.).
Procesos de negocio que asumen que “internet siempre estará ahí y mi proveedor nunca se va a caer”.
Hoy fue Cloudflare. Hace semanas fue AWS. Antes fue Azure. El patrón se repite: una parte relativamente pequeña del código o la infraestructura global se rompe… y el efecto dominó alcanza a bancos, comercios, gobiernos y startups en todo el mundo.
¿Qué pasa con bancos, fintech y pasarelas de pago si su capa de protección se cae en pleno horario comercial?
¿Qué ocurre con e-commerce, delivery o transporte si no pueden procesar pedidos, reservas o pagos por varias horas?
¿Puede un hospital, aseguradora o servicio público darse el lujo de depender de un único proveedor que, si falla, los deja desconectados?