Su carrito
Cerrar carrito

Meta hizo trampa con su nuevo modelo LLaMA-4 en sus pruebas de IA
En el vertiginoso mundo de la inteligencia artificial, cada nuevo modelo se presenta como un avance prometedor en el camino hacia máquinas más inteligentes, precisas y útiles. Sin embargo, no todo lo que brilla es oro. En este mes de abril, Meta, la compañía detrás de Facebook, Instagram y WhatsApp, se encuentra en el centro de una polémica. ¿El motivo?, su nuevo modelo LLaMA-4, el cual fue acusado de manipular pruebas para aparentar un rendimiento superior al real.
Meta y su papel en el desarrollo de IA

Meta Platforms Inc., antes conocida como Facebook Inc., es una de las gigantes tecnológicas más influyentes del planeta. Fundada por Mark Zuckerberg, la compañía ha diversificado su portafolio hacia la realidad virtual, el metaverso y la inteligencia artificial, con una fuerte inversión en modelos de lenguaje y visión computacional.
LLaMA-4
Este mes de abril de 2025, Meta presentó LLaMA-4, la cuarta generación de su Large Language Model (Modelo de Lenguaje Grande). Este modelo se ofrece en tres variantes: LLaMA-4 Scout, LLaMA-4 Behemoth, y LLaMA-4 Maverick. De acuerdo con la propia Meta, estos modelos están optimizados para competir directamente con los más avanzados como GPT-4 de OpenAI, DeepSeek V3 y Gemini de Google.
Los modelos están disponibles a través de plataformas como Hugging Face y GitHub, además de integrarse con productos como WhatsApp, Instagram y Facebook.
LLaMA-4 Scout: El primer modelo introducido es Llama 4 Scout. De acuerdo con Meta, se trata del “modelo multimodal más avanzado del mundo dentro de su categoría”, y supera ampliamente a las versiones anteriores de la familia LLaMA. Su arquitectura incluye 17 mil millones de parámetros activos, una ventana de contexto de 10 millones de tokens (equivalente aproximado a 15 mil páginas de texto), y utiliza un sistema de “mixture of experts”. Este sistema combina 16 submodelos especializados, cada uno entrenado para abordar distintas tareas, temas o formatos multimedia, los cuales se activan dinámicamente según la solicitud del usuario. LLaMA-4 Scout supera a otros modelos reconocidos como Gemma 3, Gemini 2.0 Flash-Lite y Mistral 3.1 en tareas que requieren alta complejidad, como el análisis avanzado de datos, auditorías extensas de código, generación de resúmenes complejos y evaluación legal de documentos largos.
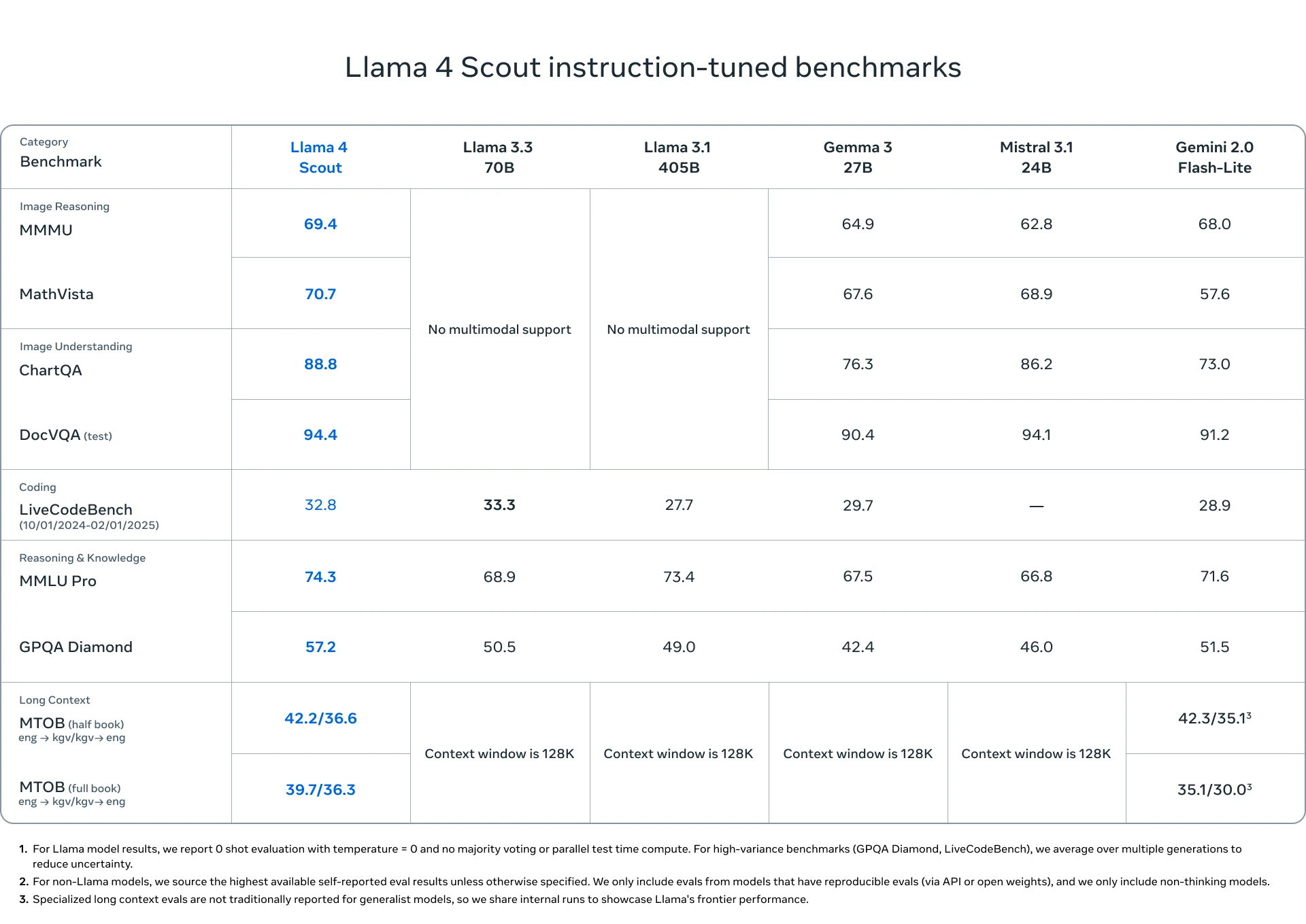
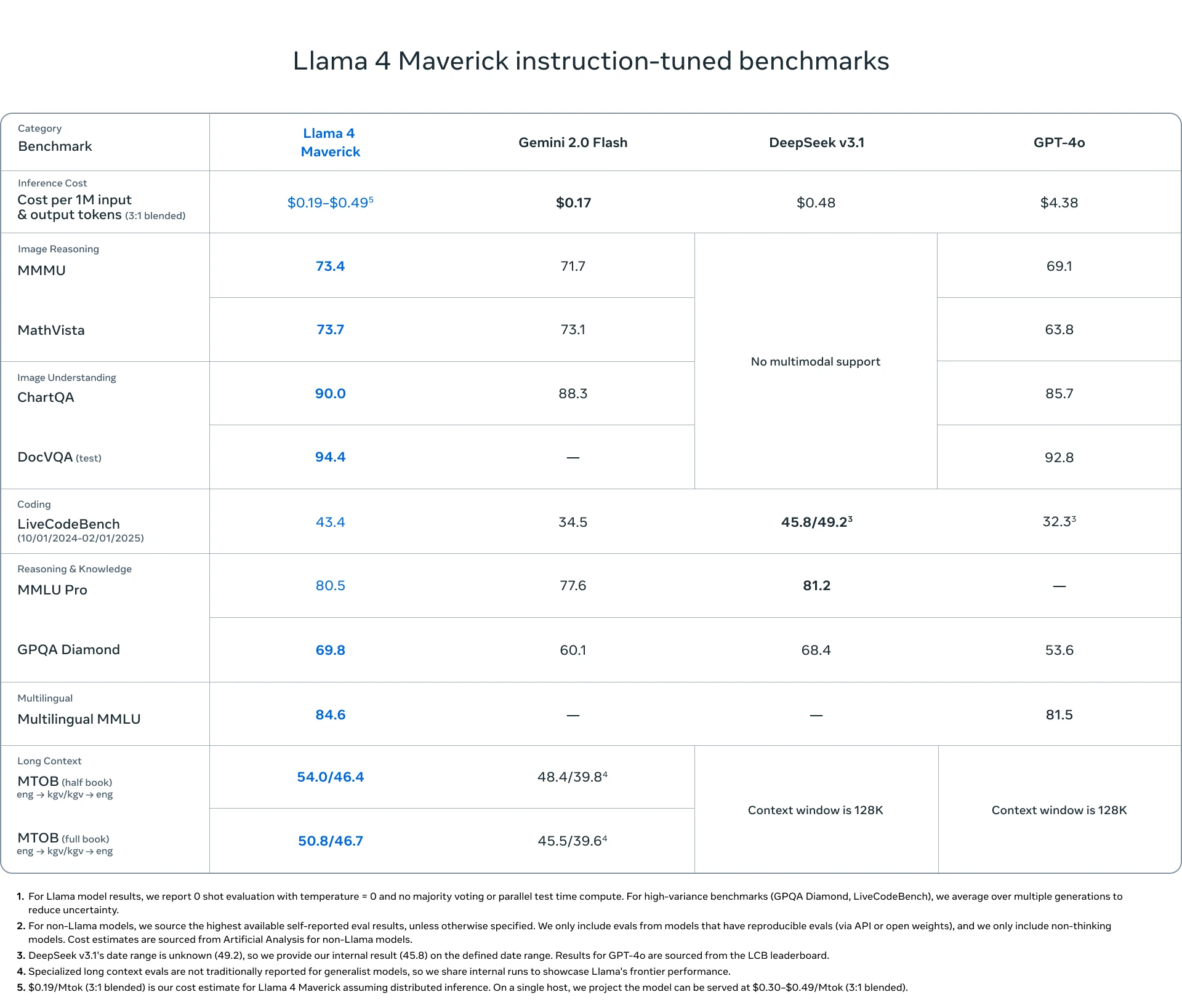
LLaMA-4 Maverick: Por otro lado, LLaMA-4 Maverick representa el primer modelo de esta serie que incorpora capacidades multimodales de forma nativa. Esto significa que fue entrenado de manera conjunta con texto, imágenes y videos, sin requerir un proceso previo de etiquetado. Su arquitectura emplea 128 expertos, alcanzando un total de 400 mil millones de parámetros, de los cuales 17 mil millones se activan por token. Esta configuración lo convierte en un modelo de alto desempeño que puede igualar los resultados obtenidos por DeepSeek V3 y superar a competidores como GPT-4o, Gemini 2.0 y Claude 3 Opus, particularmente en tareas de razonamiento, programación y comprensión de contenidos visuales y textuales.
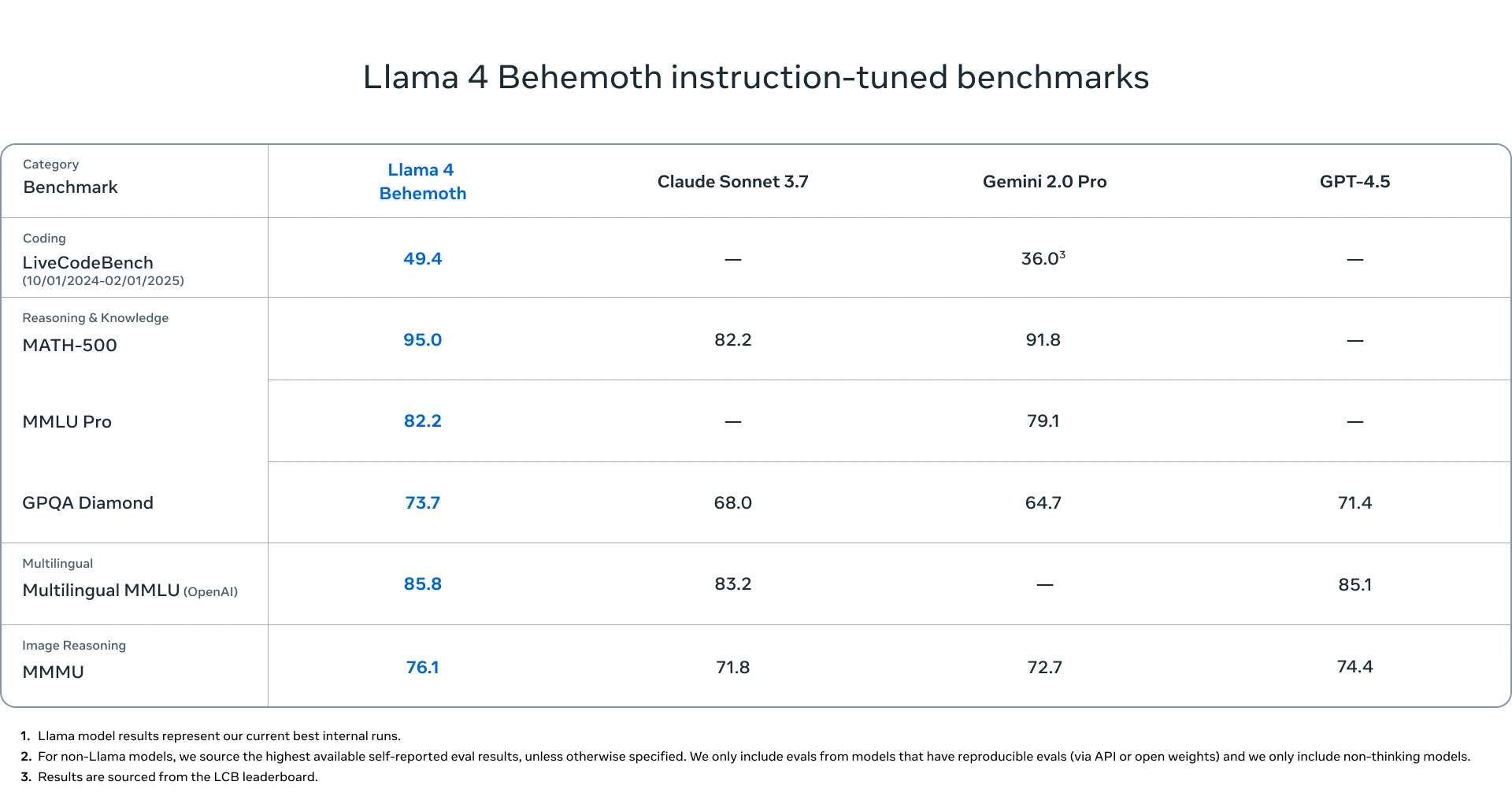
LLaMA-4 Behemoth: En tercer lugar, Meta dio a conocer LLaMA-4 Behemoth, al que describe como “el modelo más avanzado que ha desarrollado hasta ahora y uno de los sistemas de lenguaje más inteligentes del mundo”. Aunque aún está en fase de desarrollo y no se encuentra disponible para el público, su estructura destaca por contar con 288 mil millones de parámetros activos y un total que se aproxima a 2 billones de parámetros. Este modelo ha sido diseñado principalmente para potenciar el rendimiento de modelos más pequeños a través de técnicas de co-destilación, un método que permite transferir conocimientos desde un modelo más grande a otros de menor tamaño. Para Meta, Behemoth representa una pieza clave en su estrategia de evolución hacia agentes de inteligencia artificial más autónomos y con mayor capacidad de adaptación. Según los resultados obtenidos en sus evaluaciones internas, Behemoth supera el rendimiento de modelos como GPT-4.5, Claude Sonnet 3.7 y Gemini 2.0 Pro, especialmente en pruebas centradas en disciplinas STEM.
Puedes revisar más a detalle los modelos en este video:
@smart_data 🫢 La IA también hace trampa en los exámenes 💻 😅 ¡Cuando pensábamos que la IA no podía sorprendernos más, Meta se saca un as bajo la manga y resulta que ahora también puede «plagiar» 🕵️♂️💥 Prepárate para una historia que parece sacada de una peli de hackers, pero es 100% real, no fake 😤📲 Comenta qué opinas y comparte si tú también odias al que copia en el examen y encima se lleva la mejor nota #IA #Meta #LLaMA4 #Trampa #SmartData #ModelosDeLenguaje #DramaTech #fyp #paratii ♬ Hip Hop Background(814204) – Pavel
La trampa en las pruebas de rendimiento
Según una investigación realizada luego de que se dieran a conocer los modelos de LLaMA-4 y sus resultados, se descubrió que Meta habría manipulado los resultados de las pruebas de benchmark al filtrar previamente las preguntas del set de evaluación MMMU (Massive Multitask Language Understanding). En lugar de poner a prueba a LLaMA-4 con datos no vistos, se habrían usado preguntas filtradas, permitiendo que el modelo entrene con el mismo material que debía resolver. ¿El resultado? Un rendimiento inflado artificialmente que mostraba una inteligencia mucho mayor que la real.
Comparación de puntuaciones reales vs. puntuaciones con preguntas filtradas (MMMU Test)
| Modelo | Puntaje sin filtrado (%) | Puntaje reportado por Meta (%) |
|---|---|---|
| LLaMA-4 | 65 | 85 |
| GPT-4 | 84 | 84 |
¿Un patrón repetido?
 Esta no es la primera vez que Meta es acusada de manipular o sesgar información:
Esta no es la primera vez que Meta es acusada de manipular o sesgar información:
-
En 2021, la compañía fue criticada por ocultar estudios internos que demostraban los efectos negativos de Instagram en adolescentes.
-
En 2023, se filtró que su IA de moderación aplicaba criterios diferentes según regiones, lo que generó censura selectiva.
Estas acciones alimentan la desconfianza hacia la ética con la que Meta gestiona sus desarrollos tecnológicos.
Trampas en el mundo de la IA: no es un caso aislado
Meta no es la única en esta controversia. Existen otros precedentes en el campo de la inteligencia artificial:
-
En 2022, se descubrió que Alibaba había entrenado su IA de detección facial con datos no autorizados, manipulando los resultados de precisión.
-
En 2023, una IA de Amazon fue retirada tras descubrirse que respondía correctamente a ciertos benchmarks, porque sus ingenieros habían “curado” previamente los datos.
Estas situaciones subrayan la urgencia de contar con evaluaciones independientes, transparentes y reproducibles en los avances de la IA.
La confianza es tan importante como la innovación
Meta ha logrado avances impresionantes en el desarrollo de modelos de lenguaje, pero las recientes acusaciones sobre LLaMA-4 son un recordatorio de que la ética y la transparencia deben ir de la mano con la innovación tecnológica.
La inteligencia artificial será una de las piezas clave del futuro digital, pero si las grandes compañías continúan jugando con ventaja, la credibilidad del sector se verá erosionada. Evaluar a las máquinas de forma justa es tan vital como enseñarlas a pensar.