Su carrito
Cerrar carrito

¿El principio del fin del monopolio de Nvidia? Microsoft rompe el tablero con Maia 200


Durante los últimos años, el mundo de la Inteligencia Artificial ha tenido un único dueño y señor: Nvidia. La empresa dirigida por Jensen Huang no solo construyó los mejores chips, sino que cavó un foso defensivo casi infranqueable alrededor de ellos. Si querías entrenar o ejecutar modelos de IA, tenías que pagar el «peaje Nvidia»: precios altísimos, listas de espera interminables y una dependencia tecnológica absoluta de sus arquitecturas H100 y Blackwell.
Nvidia controla cerca del 95% del mercado de chips para IA. Ese monopolio ha convertido a las grandes tecnológicas en clientes cautivos, obligándoles a gastar decenas de miles de millones de dólares cada trimestre para no quedarse atrás.
Pero Microsoft, el cliente más VIP de Nvidia, acaba de decir «basta». La compañía de Redmond ha decidido que ya no quiere seguir alquilando el futuro, sino ser dueña de él.
Y la respuesta tiene nombre y apellidos: Maia 200. No es un experimento; es la carta más seria jugada hasta ahora para romper la hegemonía del silicio.
Indice
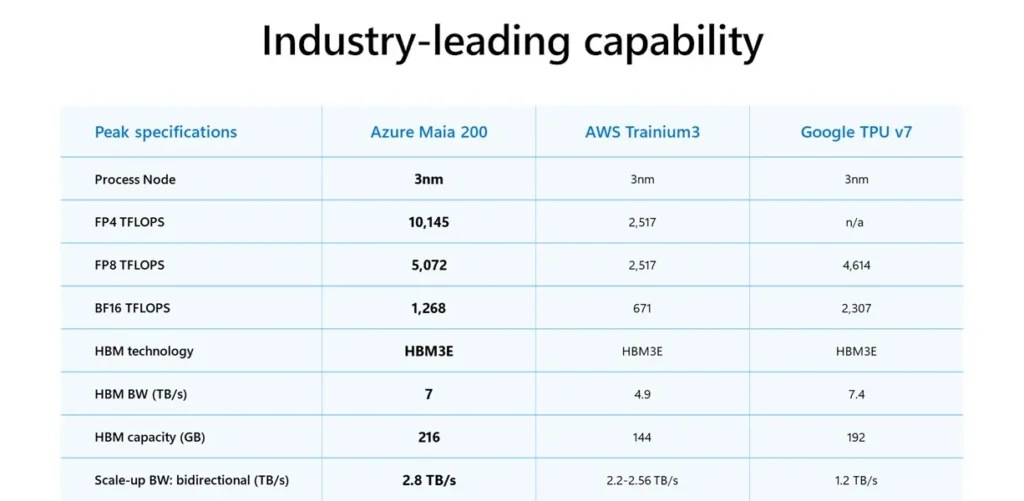
ToggleMicrosoft ha abierto el capó del Maia 200 y lo que hay dentro es ingeniería de vanguardia fabricada en el proceso de 3 nanómetros de TSMC. Pero lo interesante está en la memoria y la arquitectura:
Our newest AI accelerator Maia 200 is now online in Azure.
Designed for industry-leading inference efficiency, it delivers 30% better performance per dollar than current systems.
And with 10+ PFLOPS FP4 throughput, ~5 PFLOPS FP8, and 216GB HBM3e with 7TB/s of memory bandwidth… pic.twitter.com/UUiGikO1uB
— Satya Nadella (@satyanadella) January 26, 2026
Memoria HBM3e masiva: 216 GB con un ancho de banda de 7 TB/s.
SRAM integrada: 272 MB para mantener los datos cerca de los núcleos de cálculo.
Núcleos Tensoriales Nativos: Soporte directo para FP8 y FP4, formatos cruciales para la inferencia moderna.
Esta arquitectura resuelve el mayor cuello de botella actual: no la potencia de cálculo bruta, sino la velocidad a la que se pueden mover datos masivos dentro del chip.
Microsoft no ha tenido reparos en comparar su nuevo juguete con la competencia directa, afirmando que Maia 200 es «el silicio de primera mano más eficiente de cualquier hiperescalador». Las cifras son agresivas:
Vs. Amazon: Tres veces el rendimiento en FP4 comparado con el Trainium v3 de tercera generación.
Vs. Google: Rendimiento en FP8 superior a la TPU v7 (séptima generación).
Vs. Flota actual (Nvidia): Un 30% mejor rendimiento por dólar.
Quizás el dato más explosivo del anuncio no es el hardware, sino el software. Microsoft ha confirmado oficialmente que Maia 200 servirá para múltiples modelos, incluidos los todavía inéditos GPT-5.2 de OpenAI.
Esto confirma dos puntos críticos:
La simbiosis entre OpenAI y Microsoft es total.
El equipo de Microsoft Superintelligence ya está utilizando estos chips para la generación de datos sintéticos y aprendizaje por refuerzo, acelerando el ciclo de entrenamiento de la próxima generación de modelos.
Para evitar caer donde otros fallaron, Microsoft ha acompañado el chip con un ecosistema de software robusto. El nuevo SDK de Maia incluye integración nativa con PyTorch, un compilador Triton y acceso a programación de bajo nivel. Esto permite a los desarrolladores exprimir el chip al máximo sin la fricción habitual de migrar desde Nvidia.
Y no es una promesa de PowerPoint: el hardware ya está desplegado y operativo en la región de centros de datos de Central US (Iowa) y próximamente se encenderá en Phoenix, Arizona
La pregunta no es si Nvidia va a desaparecer mañana; su tecnología sigue siendo puntera. La pregunta real es financiera: ¿Por qué seguir pagando el precio premium de Nvidia para inferencia cuando puedes tener algo un 30% más eficiente en casa?
Con Maia 200, Microsoft no solo reduce costos; envía un mensaje claro a la industria: el monopolio del hardware de IA ya no es invencible.